
Published on | MyDataScraper
Welcome to the very first edition of the MyDataScraper Data Digest, our monthly roundup of the developments that are reshaping how we collect, use, and think about public web data. May 2026 has been nothing short of seismic: the EU AI Act is finally in full swing, travel data providers are pulling up the drawbridge, and eCommerce scraping faces yet another courtroom test. Whether you’re building a price comparison engine, training LLMs, or running a travel aggregator, these shifts directly affect your stack.
We’ve done the reading so you don’t have to. Pour a coffee, and let’s dig in.
1. AI Regulation: The EU AI Act and What It Means for Web Scraping
On May 1, 2026, the most ambitious AI regulatory framework in the world entered its final enforcement phase. The EU Artificial Intelligence Act (Regulation 2024/1689) is now fully applicable, and it’s sending ripples far beyond the world of model developers. Data professionals everywhere are asking the same question: does the AI Act affect my web scraping operation?
The short answer is yes, indirectly but powerfully. Here’s why.
The Data → AI Pipeline Under Scrutiny
The AI Act doesn’t regulate web scraping per se. That remains under the GDPR, the Digital Services Act, and the Database Directive. However, the Act creates a new layer of responsibility for anyone who supplies data used to train or operate AI systems — and that includes providers of scraped datasets, API feeds, and real‑time data streams.
Under Article 10, “Data and Data Governance,” providers of high‑risk AI systems must use training, validation, and testing datasets that are:
- Relevant, representative, and free from errors
- Subject to documented data governance practices
- Assessed for potential biases
If your scraped data flows into a high‑risk AI (e.g., credit scoring, recruitment, insurance pricing), the organisation using that AI must now trace the provenance of its data and ensure you collected it lawfully. In practice, this means buyers of scraped data will demand transparency: where did you scrape it, when, how, and under what legal basis?
Key Provisions Affecting Data Collectors
| AI Act Article | What It Requires | Impact on Scraping |
|---|---|---|
| Article 10 – Data governance | Document bias checks, data sources, and preprocessing steps | Scraped datasets must come with provenance reports; “black box” data dumps are out |
| Article 13 – Transparency | Inform users when they interact with AI | If scraped data powers a chatbot or price engine, the end product must disclose that |
| Article 50 – GPAI (General Purpose AI) | Providers of GPAI models must publish a summary of training data | LLM trainers will need to list data sources; scraped web data will be visible to regulators |
| Recital 105 | Alignment with GDPR on lawful basis for processing | Scraping that involves personal data (even unintentionally) falls under “legitimate interest” assessments |
What You Should Do Now
- Document everything. Every scrape job needs a record: source URL, time, frequency, compliance checks. If you’re selling scraped data, buyers will ask for this.
- Audit for personal data. Even publicly accessible profiles contain PII. The AI Act reinforces the GDPR requirement that you have a lawful basis for processing that data.
- Label your datasets. Expect “data nutrition labels” to become standard. Include collection methodology, known biases, and update frequency.
- Revisit terms of service. The AI Act gives more weight to the “expressed wishes” of data subjects. If a website explicitly forbids scraping in its ToS, using that data for AI training may become legally riskier.
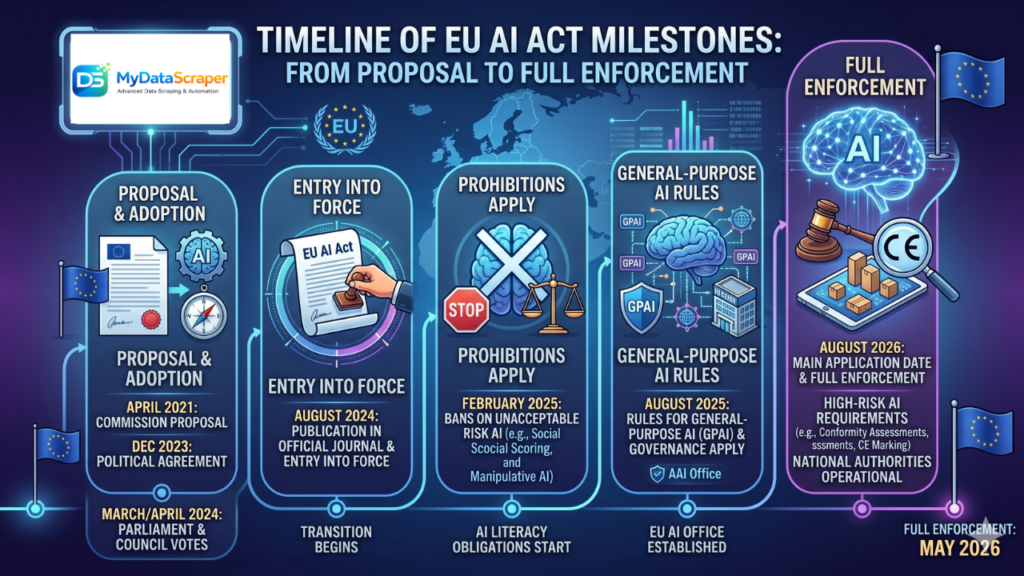
Bottom line: The AI Act doesn’t ban scraping, but it adds a heavy documentation and transparency burden. Data providers that can demonstrate clean provenance will command a premium. At MyDataScraper, we’re already building automated provenance logs into our scraping APIs to keep you ahead of the curve.
2. Travel API Changes: Shifting Sands for Aggregators and OTAs
If you operate a travel meta‑search site, a hotel price comparison app, or a flight deal newsletter, you’ve probably felt the ground move beneath your feet in the past two months. Major travel data pipelines are being redesigned, restricted, or retired entirely.
The Google Travel Shake‑Up
In April 2026, Google quietly deprecated the free tier of its Travel Partner API for hotel prices and availability. This API, which powered countless small aggregators and academic travel studies, now requires a commercial license with minimum monthly commits. Combined with the December 2025 removal of the “Things to Do” API, many startups are left scrambling for alternatives.
Simultaneously, the EU Digital Markets Act (DMA) has forced Google to share more real‑time hotel price parity data with competitors — but only through tightly controlled, approved gateways. The irony? More data exists, but access is gated behind complex legal agreements that small teams struggle to negotiate.
OTAs Tighten Their Data Faucets
Booking.com and Expedia have both updated their affiliate API terms in Q1 2026, introducing stricter rate limits and prohibitions on storing cached price data. The new clauses effectively target scraping‑based models that fall outside their official affiliate programmes. One notable change: cached prices can no longer be displayed without a live availability check, which increases dependency on their real‑time endpoints and can slow down your site.
What About Airline Data?
Airline booking data remains a fortress. The Fareportal vs. American Airlines case (settled in March 2026) saw Fareportal agree to stop scraping AA’s site and to only access data through AA’s NDC API. This settlement cements a trend: more carriers are suing scrapers and pushing aggregators toward official, paid NDC channels. The cost per query is now measurable in cents, a bitter pill for low‑margin OTAs.
Opportunity in Crisis: The Rise of Alternative Travel Data Sources
As the big pipes narrow, innovative data teams are turning to alternate public sources: hotel websites themselves, local tourism board listings, even crowdsourced check‑in data. That’s where a flexible, custom scraping infrastructure becomes your competitive moat.
| Data Need | Traditional API Source | Alternative Public Web Source |
|---|---|---|
| Hotel prices | Google Travel Partner API, OTAs | Direct hotel booking engines (Marriott.com, Hilton.com, independent hotels) |
| Airline fares | NDC APIs, Farelogix | Airline public‑facing search pages (carefully, within legal limits) |
| Vacation rentals | Airbnb API (tightly controlled) | Public listing pages, regional property manager sites |
| Attraction & activity data | Google Things to Do (deprecated) | Viator, GetYourGuide public listings, local DMO sites |
We’ve already helped three travel aggregators migrate from deprecated APIs to bespoke scraping feeds that pull from direct hotel sites and public listings. The result? Lower per‑query costs and more up‑to‑date prices than the affiliate channels provide. If you’re facing an API cliff, reach out — we can likely build a compliant bridge.
3. eCommerce Scraping News: Courtrooms, CAPTCHAs, and Crackdowns
The eCommerce scraping arena never sleeps. May 2026 has brought fresh legal rulings, aggressive anti‑bot tech, and a surprising regulatory twist that actually supports data access in certain cases.
Legal Roundup: Two Cases to Watch
Meta v. Bright Data – The Supreme Court Denies Cert (April 28, 2026)
The US Supreme Court declined to hear Meta’s appeal in its long‑running case against Bright Data. The lower court’s ruling stands: scraping public data from websites where no login or paywall is involved does not violate the Computer Fraud and Abuse Act (CFAA). This is a massive win for the scraping industry, though it’s not a free pass. The ruling explicitly left open the possibility of breach of contract claims if terms of service are clearly and conspicuously presented.
Takeaway: The “public data is fair game” principle is stronger than ever, but you still need to read ToS and avoid circumventing authentication. Consent banners and clickwraps are now the frontline of legal risk.
Amazon vs. Competitor Scrapers – A New Antitrust Allegation (Filed May 1, 2026)
In a twist, a coalition of eCommerce analytics startups has filed an antitrust complaint against Amazon, alleging that the company’s increasingly aggressive anti‑scraping measures (including CAPTCHA loops, IP blocks, and legal threats) are designed to foreclose competition in the price comparison market. The complainants argue that since Amazon is a dominant marketplace, preventing access to its publicly listed prices harms consumers. This complaint is in its infancy, but it could open a new line of defence for scrapers.
Tech Arms Race: AI‑Driven Anti‑Bot Systems
On the technical side, platforms like Shopify, Amazon, and Walmart are now deploying AI‑based bot detection that goes far beyond simple CAPTCHAs. These systems analyse mouse movements, rendering consistency, and even interaction patterns to distinguish humans from machines. In response, scraping engineers are moving toward browser automation with human‑like behaviour emulation, using modern frameworks like Playwright with stealth plugins.
But be warned: the line between sophisticated scraping and “bot fraud” is getting thinner. Use these techniques only where you have a clear legal right to access the data, and always respect robots.txt and rate limits.
Price Scraping for Good: The Consumer Protection Win
Not all eCommerce scraping news is doom and gloom. In February 2026, the US Federal Trade Commission (FTC) explicitly endorsed the use of price scraping by consumer watchdog organisations to detect dynamic pricing anomalies and deceptive discount practices. The FTC’s report cited scraped data that exposed retailers inflating “original” prices before sales. This governmental endorsement could strengthen the “public interest” argument in future scraping cases.
What eCommerce Data Collectors Should Do Right Now
- Rely on public data. The Meta v. Bright Data outcome encourages scraping of non‑login pages. Stay firmly in that zone.
- Stay polite. Rate limit aggressively, rotate IPs ethically, and never slam a server. Good citizenship is your best legal shield.
- Document your public interest purpose. If you’re doing price comparison for consumers, state it explicitly in your business records and on your site.
- Use robust infrastructure. Anti‑bot systems are getting smarter. A raw Python script won’t cut it anymore. Use professional scraping services that handle the tech and compliance for you.
Industry Implications & What’s Around the Corner
If there’s one theme that ties these three stories together, it’s this: the era of “just grab the data” is over. Whether you’re training AI, comparing travel prices, or tracking eCommerce listings, you now operate in a high‑visibility, high‑accountability environment. Regulators are watching, platforms are pushing back, and your customers demand squeaky‑clean data provenance.
This isn’t a bad thing. It separates serious data professionals from fly‑by‑night scrapers. And it creates a massive opportunity for those who invest in compliant, reliable data infrastructure now. At MyDataScraper, we’re betting on a future where every data point carries a provenance trail, and scraping is as boring and trusted as an API call.
Looking Ahead to June 2026
- GDPR enforcement wave: Several European DPAs have announced a coordinated investigation into AI‑training data practices. Expect more clarity on “legitimate interest” for scraping.
- Travel API consolidation: Rumours of a Sabre‑Amadeus NDC partnership could reshape airline data access.
- US federal scraping law? A bipartisan draft bill on “Digital Transparency and Fair Access” is circulating. It may codify some of the Bright Data principles into law.
Final Thoughts
The data world moves fast, and the only way to stay ahead is to keep learning, keep adapting, and keep your pipelines clean. We hope this first Data Digest gave you a useful map of the landscape. If you want help navigating any of these shifts — whether it’s building a provenanced dataset for AI training, setting up a travel scraping feed that replaces a dying API, or ensuring your eCommerce collection is bulletproof — our team is ready.
🧠 Want a data solution that keeps up with regulatory and tech changes?
Talk to our experts and get a free consultation on your data collection strategy.Discuss Your Project
Disclaimer: The information in this Data Digest is for informational purposes only and does not constitute legal advice. Always consult a qualified attorney for your specific situation. All company names and trademarks are the property of their respective owners.