Why Financial Data Is the Ultimate Competitive Edge
In financial markets, information is money. The investor who knows a company’s earnings trajectory before consensus estimates update wins. The analyst who spots a macroeconomic trend signal two weeks before it appears in official reports wins. The fintech company that builds its platform on fresher, wider, and more granular data than its competitors wins. In every case, the edge comes from the same source: better financial data, collected faster and at greater scale than anyone else in the room.
Yet most financial professionals are still constrained by expensive, slow, and narrow data vendors — Bloomberg terminals at $25,000 per year, Reuters feeds with rigid data schemas, and quarterly filings that arrive weeks after the markets have already priced the information. Meanwhile, the most sophisticated investors on Wall Street and in quantitative hedge funds have been building alternative data pipelines through web scraping for years — extracting signals from hundreds of sources that traditional vendors don’t cover, faster than any subscription service delivers.
In 2026, web scraping for financial data is no longer just a hedge fund secret weapon. Accessible, affordable custom scraping solutions — like those built by MyDataScraper — are democratizing access to sophisticated financial intelligence for independent investors, boutique investment firms, financial analysts, and fintech companies building the next generation of financial data products.
Global financial data market size in 2026 and growing at 14% annually
Of quantitative hedge funds use alternative data from web scraping as a primary alpha source
Better risk-adjusted returns reported by investors using alternative data vs traditional sources
Average time advantage that web-scraped financial data has over traditional vendor delivery
What Is Web Scraping for Financial Data?
Web scraping for financial data is the automated collection of publicly available financial information — stock prices, earnings reports, economic indicators, SEC filings, company financials, market news, analyst estimates, commodity prices, cryptocurrency data, real estate investment metrics, and alternative financial signals — from websites, financial portals, regulatory databases, and online financial communities.
This is fundamentally different from subscribing to a financial data vendor. Instead of receiving a standardized data feed from a single provider’s curated database, web scraping builds a custom intelligence pipeline that:
- Covers any source — not just the sources your vendor decided to include
- Delivers data faster — from the moment it’s published publicly, not after vendor processing
- Costs dramatically less — at a fraction of premium vendor subscription costs
- Scales infinitely — from 10 securities to 10,000 without changing your cost structure
- Captures alternative signals — the non-traditional data sources that generate real alpha
- Delivers in your format — CSV, JSON, or Excel or directly into your analysis systems
The Alternative Data Revolution: “Alternative data” — financial intelligence derived from non-traditional sources like web scraping of news sentiment, job posting trends, satellite imagery metadata, social media signals, and web traffic patterns — is now the primary source of alpha generation for the world’s most sophisticated investors. Web scraping is the core collection mechanism behind this revolution.
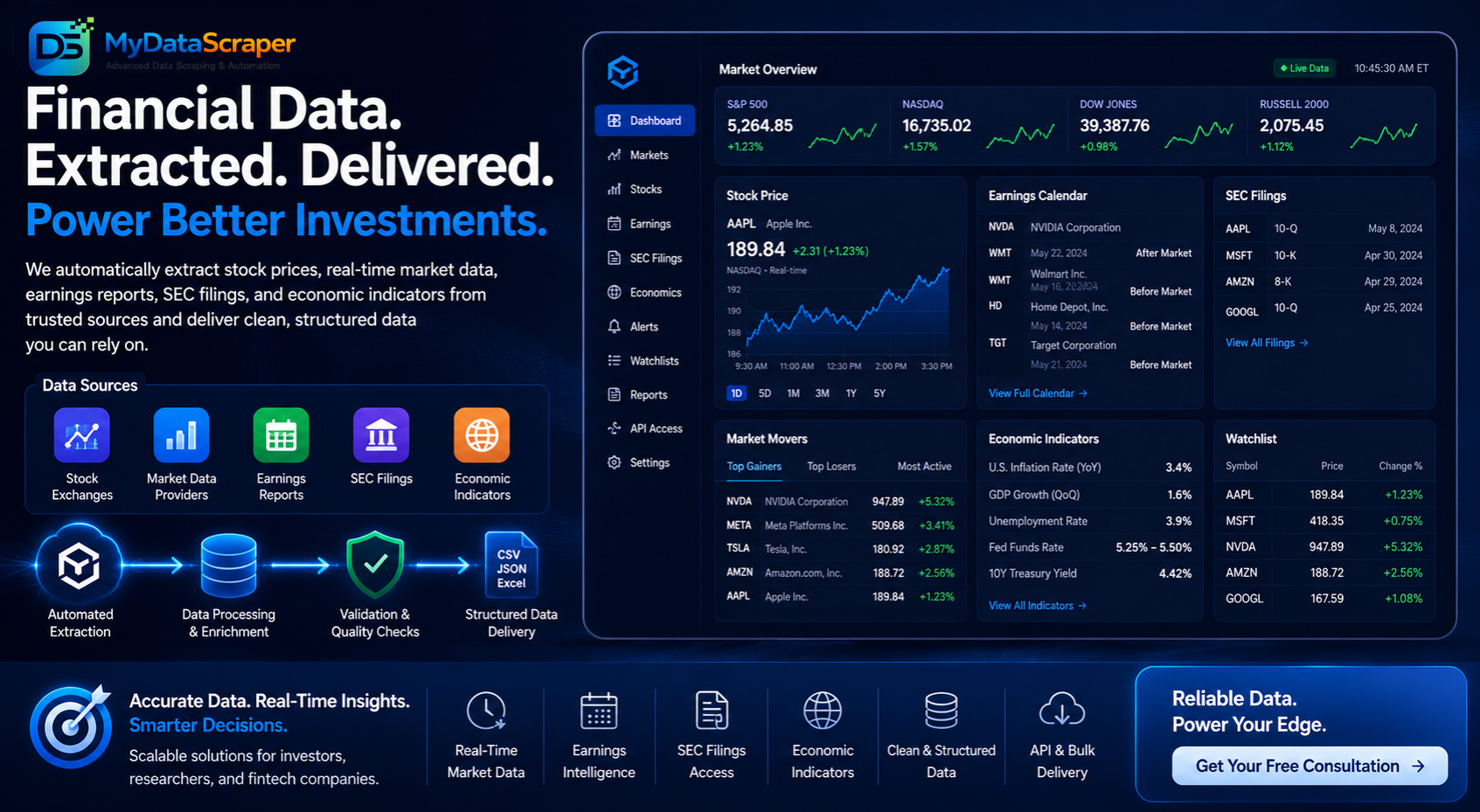
Financial Data Extraction in Action: The Market Terminal
Here’s a visualization of what a financial data extraction dashboard looks like when powered by web scraping — the kind of structured market intelligence MyDataScraper delivers automatically:
| Ticker | Price | Change | Volume | Mkt Cap | Source | Status |
|---|---|---|---|---|---|---|
| AAPL | $196.42 | +2.18 (+1.12%) | 89.4M | $3.02T | Yahoo Finance | ● LIVE |
| NVDA | $142.87 | +4.91 (+3.56%) | 312.7M | $3.49T | MarketWatch | ● LIVE |
| TSLA | $248.19 | -6.43 (-2.52%) | 145.2M | $792B | Seeking Alpha | ● LIVE |
| MSFT | $452.30 | +3.87 (+0.86%) | 22.8M | $3.36T | Finviz | ● LIVE |
| BTC/USD | $97,842 | -2,341 (-2.33%) | $48.2B | $1.93T | CoinMarketCap | ● LIVE |
| 10Y UST | 4.284% | +0.032 | — | — | Treasury.gov | ✓ DONE |
Beyond simple price feeds, our financial data extraction solutions deliver earnings reports the moment they’re filed, news sentiment scores updated hourly, economic indicator releases from government databases, SEC filing data within minutes of publication, and alternative financial signals from hundreds of sources — all in a single, automated, continuously updated intelligence pipeline.
Why Financial Intelligence Matters More Than Ever in 2026
Markets Move on Information Asymmetry
Every profitable trade, every successful investment thesis, every well-timed portfolio rebalancing is ultimately driven by some form of information advantage. In efficient markets, the edge comes from having better data — more sources, faster delivery, deeper coverage — than the consensus. Web scraping for financial data is the most effective tool for building and sustaining this information advantage at scale.
Traditional Vendor Data Is Commoditized
When every institutional investor is subscribing to the same Bloomberg terminal, the same Reuters data feed, and the same FactSet earnings estimates — the data itself becomes a commodity. No edge can be sustained from information that every competitor also has. The edge lives in the data sources that aren’t yet in everyone’s terminal — and that’s exactly where web scraping operates.
Alternative Data Is Now the Primary Alpha Generator
Research from J.P. Morgan, Goldman Sachs, and academic finance departments consistently shows that alternative data — web-scraped signals from job postings, web traffic, pricing changes, news sentiment, patent filings, and hundreds of other non-traditional sources — generates statistically significant alpha in equity portfolios, particularly when combined with traditional fundamental analysis.
Fintech Products Are Built on Data Differentiation
Every fintech company competing in wealth management, lending, insurance pricing, credit risk, or investment analytics needs a proprietary data advantage. The companies winning this space aren’t just using what Bloomberg sells — they’re building custom financial data pipelines through automated financial data extraction that powers products their competitors simply cannot replicate.
“The democratization of alternative data through web scraping is the most significant structural change in investment research in the last decade. The firms that build proprietary data pipelines today are building moats that will compound for years — the firms that don’t are slowly but surely giving away their edge.” — Quantitative Investment Research, 2026
Top Financial Data Sources You Can Scrape
The financial web is rich with publicly accessible data. Here are the primary source categories from which MyDataScraper extracts financial intelligence:
Financial Market Portals
Yahoo Finance, MarketWatch, Finviz, Seeking Alpha, TheStreet, and Motley Fool publish real-time and historical stock prices, analyst ratings, earnings estimates, and fundamental financial metrics accessible for systematic extraction.
Regulatory & Government Databases
SEC EDGAR (earnings, 10-K, 10-Q, 8-K filings), Federal Reserve economic data (FRED), Bureau of Labor Statistics, Census Bureau economic reports, and Treasury yield data — all publicly accessible and extractable in real time.
Cryptocurrency Platforms
CoinMarketCap, CoinGecko, CryptoCompare, and major exchange data for spot prices, trading volume, market cap rankings, DeFi protocol metrics, and on-chain analytics data for digital asset intelligence.
Financial News & Media
Reuters, Bloomberg (public articles), Financial Times, Wall Street Journal public content, CNBC, business wire press releases, and company investor relations pages for real-time news sentiment and event monitoring.
Alternative Financial Signals
Job posting platforms (hiring trends as company growth signals), web traffic data (revenue proxy), patent databases (innovation pipeline intelligence), import/export records (supply chain intelligence), and earnings call transcripts for sentiment extraction.
Company Financial Disclosures
Annual reports, quarterly earnings releases, investor presentations, ESG disclosures, proxy statements, and management guidance documents directly from company investor relations websites — parsed and structured automatically.
Economic & Macro Databases
World Bank, IMF, OECD, Eurostat, central bank websites across major economies — extracting GDP growth, inflation, unemployment, trade balance, and policy rate data for macro investment analysis.
Financial Social Intelligence
Reddit (r/investing, r/WallStreetBets, r/stocks), StockTwits, financial Twitter/X sentiment, and Quora investment discussions — monitoring retail investor sentiment as a contrarian or momentum signal.
Complete Financial Data Dictionary: What Can Be Extracted
The breadth of extractable public financial data is remarkable. Here’s a comprehensive reference for the data categories and specific fields available through financial data extraction:
| Data Category | Specific Extractable Fields | Investment Application |
|---|---|---|
| Equity Price Data | Open, high, low, close, adjusted close, volume, VWAP, pre/post market prices | Technical analysis, backtesting, trading signal generation |
| Fundamental Metrics | P/E, P/B, EV/EBITDA, revenue, earnings, margins, ROE, debt ratios, free cash flow | Valuation analysis, stock screening, peer comparison |
| Earnings Data | EPS actual vs estimate, revenue actual vs estimate, guidance, beat/miss history | Earnings surprise modeling, event-driven strategies |
| SEC Filings | 10-K, 10-Q, 8-K content, insider transactions, institutional holdings (13F) | Corporate governance, insider signal tracking, position monitoring |
| Analyst Intelligence | Rating changes, price target revisions, consensus estimates, recommendation distribution | Sentiment tracking, coverage initiation signals, estimate revision momentum |
| Economic Indicators | CPI, PPI, GDP, unemployment rate, PMI, retail sales, housing starts, Fed funds rate | Macro investment thesis, sector rotation, rate sensitivity analysis |
| Fixed Income Data | Treasury yields (all maturities), corporate bond spreads, credit ratings, yield curves | Duration management, credit analysis, relative value |
| Commodity Prices | Crude oil, gold, silver, agricultural commodities, natural gas, metals spot prices | Commodity trading, sector analysis, inflation hedging |
| Cryptocurrency Data | Spot prices, market cap, trading volume, dominance, DeFi TVL, on-chain metrics | Digital asset allocation, DeFi analysis, correlation modeling |
| Alternative Signals | Job posting volume, web traffic indices, news sentiment scores, patent filing counts | Alpha generation, early trend identification, earnings preview |
At MyDataScraper, we extract exactly the data categories and fields your investment process requires — delivered in CSV, JSON, or Excel, integrated into your quantitative models, risk systems, or research platforms.
Use Cases: Who Needs Financial Data Scraping?
Quantitative Investors & Hedge Funds
Build systematic trading signals from alternative data sources — job posting trends, web traffic indices, news sentiment, and pricing data — that generate alpha uncorrelated with traditional factor models.
Fundamental Investment Analysts
Monitor earnings releases, analyst estimate revisions, SEC filings, management commentary, and competitor data for every company in your coverage universe — automatically, in real time.
Fintech & Financial Data Companies
Build proprietary financial data products and platforms on top of custom-scraped datasets — powering robo-advisors, credit scoring models, alternative lending platforms, and investment analytics tools.
Investment Banks & Boutiques
Power M&A research, equity research, fixed income analysis, and due diligence with comprehensive data extraction from regulatory filings, financial databases, and alternative intelligence sources.
Retail Investors & Independent Traders
Access professional-grade financial data intelligence previously only available to institutional investors — earnings surprises, insider transactions, analyst revisions, and alternative signals — at a fraction of institutional data costs.
Macro Economists & Policy Researchers
Build comprehensive economic databases by extracting indicators from multiple national statistics agencies, central bank publications, and international financial institutions simultaneously.
Risk Management & Compliance Teams
Monitor regulatory filings, news sentiment around portfolio positions, counterparty financial health indicators, and ESG controversy signals for comprehensive risk intelligence.
Real Estate Investment Analysts
Extract REIT financial metrics, property market data, mortgage rate trends, rental yield data, and commercial real estate transaction records for real estate investment analysis and portfolio management.
Financial Journalists & Research Platforms
Power financial journalism, research publications, and investor education platforms with automatically updated financial data, market metrics, and economic intelligence without manual data collection.
Web Scraping vs Financial Data APIs & Expensive Vendors
Let’s compare automated financial data extraction against the traditional approaches to financial data access:
| Dimension | ❌ Traditional Data Vendors | ✅ Web Scraping Solutions |
|---|---|---|
| Annual Cost | $25K–$300K+ (Bloomberg etc.) | Fraction of vendor cost |
| Data Source Coverage | Vendor’s curated sources only | Any public source on the web |
| Alternative Data Access | Expensive premium add-ons | Built-in — any source |
| Data Delivery Speed | Vendor processing lag (hours) | Minutes from publication |
| Historical Data Depth | Vendor’s archive limits | Build unlimited history |
| Custom Data Fields | Vendor’s predefined schema | Any field on any page |
| Scalability | User/terminal seat pricing | Scale without added cost |
| Data Exclusivity | Thousands of subscribers | Proprietary to your firm |
| Niche Market Coverage | Major markets only | Any market, any region |
| Integration Flexibility | Vendor’s API only | CSV, JSON, Excel, any API |
Best Practice: Most institutional investors use web scraping to supplement (not replace) core vendor data — using Bloomberg or Reuters for core pricing and corporate actions, while building custom scraping pipelines for alternative signals, niche market coverage, and any data not available in vendor feeds. This hybrid approach maximizes intelligence breadth while controlling costs.
Financial Sectors Winning with Data Scraping
| Financial Sector | Primary Data Sources Scraped | Key Intelligence Generated | Edge Created |
|---|---|---|---|
| Equity Long/Short | SEC filings, job boards, news, web traffic | Earnings preview signals, management sentiment | Alpha generation, risk management |
| Quant / Algorithmic Trading | Multi-source price feeds, alt data signals | Factor construction, signal backtesting | Systematic edge, reduced model decay |
| Credit & Fixed Income | Regulatory filings, news, economic databases | Credit risk signals, spread drivers | Earlier credit deterioration detection |
| Macro / Global Investing | Central banks, statistics agencies, IMF/World Bank | Economic indicator forecasting | Macro timing, currency positioning |
| Venture Capital & PE | Startup news, patent databases, hiring data | Deal flow intelligence, portfolio monitoring | Better due diligence, faster sourcing |
| Real Estate Investment | Property databases, REIT filings, mortgage data | Cap rate trends, market cycle signals | Better entry/exit timing, yield optimization |
| Cryptocurrency | Exchanges, DeFi platforms, on-chain sources | Market sentiment, liquidity signals | Trading edge, risk-adjusted returns |
| Wealth Management | Market data portals, economic databases | Portfolio analytics, client reporting data | Differentiated client intelligence |
The Financial Data Extraction Process: Step by Step
Here’s exactly how MyDataScraper builds and operates a custom financial data extraction pipeline:
-
📋 Investment Intelligence Requirements Scoping
We begin with a detailed scoping session to understand your investment strategy, target securities or markets, specific data fields required, frequency needs, and how the data will integrate with your existing analysis workflows and systems.
-
🗺️ Source Identification & Prioritization
Based on your intelligence requirements, we identify and prioritize the specific financial websites, regulatory databases, news sources, and alternative data platforms that will yield the highest-quality, most relevant signals for your investment process.
-
🔧 Custom Financial Scraper Engineering
Our engineering team builds scrapers purpose-built for financial data sources — handling real-time price feeds, paginated filing databases, JavaScript-rendered financial charts, rate-limited regulatory portals, and any other technical complexity specific to financial web infrastructure.
-
⏱️ Frequency & Alert Configuration
Financial data freshness requirements vary enormously — from millisecond tick data to quarterly regulatory filings. We configure collection frequencies precisely matched to your investment process, with real-time alerts for market-moving events like earnings releases, analyst rating changes, or significant price movements.
-
🧹 Financial Data Cleaning & Standardization
Raw financial data requires specialized cleaning — corporate action adjustments, currency normalization, fiscal year alignment, duplicate filing removal, outlier detection, and data type validation. We apply financial-domain expertise to deliver investment-grade data quality.
-
🔗 Analytics Platform Integration
Financial data is delivered in your preferred format — CSV, JSON, or Excel — or integrated directly with your quantitative research platform (Python, R, MATLAB), portfolio management system, risk engine, Bloomberg API supplement, or SQL/NoSQL database via automated pipeline.
-
📈 Continuous Monitoring & Quality Assurance
Financial data quality is mission-critical. We implement automated data quality checks, anomaly detection, and completeness monitoring to ensure every data point you receive meets investment-grade accuracy standards — with immediate alerts if any quality issues are detected.
-
🔄 Adaptive Maintenance & Source Evolution
Financial websites update constantly, regulatory filing formats change, and new data sources emerge. Our team proactively monitors your scrapers and adapts them to any source changes — ensuring your financial data pipeline runs uninterrupted through every market cycle.
ROI: Manual vs Automated Financial Data Collection
Let’s put concrete numbers to the comparison between a traditional manual financial data research operation and a custom automated financial data extraction solution from MyDataScraper for a mid-size investment firm covering 200 equity positions:
❌ Manual Financial Data Research
✅ Automated Financial Scraping
The Numbers: In this scenario, switching to automated financial data extraction saves $13,700 per month ($164,400 per year) while increasing coverage by 10x, adding 34 alternative data sources, reducing data lag from 24-72 hours to under 15 minutes, and extending coverage to 24/7/365. For any investment firm, this is a transformational operational upgrade — not just a cost saving.
How a Quantitative Investment Firm Built Proprietary Alpha Using Web-Scraped Alternative Data
A quantitative investment firm managing a $400M equity long/short portfolio was facing the classic quant problem: factor crowding. Their signals — momentum, value, quality — were generating diminishing returns as hundreds of competing quant strategies converged on the same data sources and the same factor exposures. They needed genuinely differentiated data to build uncorrelated signals.
After partnering with MyDataScraper, we built a comprehensive alternative data extraction pipeline covering four primary signal categories:
The Alternative Data Pipeline Built
- Job Posting Intelligence: Daily extraction of job posting volume and role type changes for every company in their coverage universe — using hiring velocity as a leading indicator of revenue and margin trajectory
- News Sentiment Scoring: Real-time extraction and sentiment classification of news articles mentioning portfolio companies — with tiered alerts for significant sentiment shifts
- SEC Filing Intelligence: Automated extraction of 10-K/10-Q language changes, 8-K event monitoring, and insider transaction alerts within minutes of EDGAR publication
- Earnings Estimate Revision Aggregation: Multi-source aggregation of analyst estimate revisions across 12 financial portals — building a consensus revision momentum signal faster than any single vendor
All data was delivered daily in structured CSV format directly into their Python-based quantitative research environment, with real-time JSON webhooks for time-sensitive events.
Investment Performance Results (18 Months)
Sharpe ratio improvement from adding alternative data signals to existing model
Annualized alpha improvement attributable to alternative data signals
Reduction in maximum drawdown through better early warning signals
Annual data cost savings vs equivalent coverage from traditional data vendors
The alternative data advantage is real, measurable, and accessible to investment firms of all sizes. The barrier is no longer cost or technology — it’s knowing how to build the right data pipelines. Contact MyDataScraper today and let’s design your financial intelligence solution.
Stop Paying Vendor Prices for
Yesterday’s Financial Data
MyDataScraper builds custom financial data extraction solutions that deliver fresher data, wider coverage, and genuine alternative data signals — at a fraction of traditional vendor costs. CSV, JSON, or Excel. Integrated with your research systems. Starting within days.
📈 Get Your Free Financial Data Consultation Explore all our services at www.mydatascraper.comHow MyDataScraper Delivers Investment-Grade Financial Intelligence

At MyDataScraper, we understand that financial data quality is not just a technical specification — it’s the foundation of investment decisions that move real capital. Here’s what makes our financial data extraction approach uniquely suited to the investment industry:
📐 Investment-Domain Expertise
We understand financial data — corporate actions, fiscal year conventions, currency normalization, earnings revision dynamics, and regulatory filing structures. This domain knowledge is embedded in how we build, clean, and deliver financial data, ensuring you receive genuinely investment-grade intelligence rather than raw web data that requires extensive downstream cleaning.
⚡ Speed as a Competitive Advantage
In financial markets, minutes matter. Our infrastructure is engineered for speed — delivering earnings releases within minutes of SEC publication, news sentiment updates within an hour of article publication, and real-time alerts for market-moving events via webhook, email, or Slack integration.
🔗 Seamless Research Platform Integration
Financial data is delivered in the format and via the channel that eliminates friction in your research workflow — CSV, JSON, or Excel delivery, direct Python/R data frame feeds, SQL database pushes, Bloomberg API supplements, or FactSet integration. Your quant team gets data where they already work.
🌍 Any Market, Any Asset Class
We build financial data solutions for equities, fixed income, commodities, cryptocurrencies, real estate, private markets, and macro economic data — across US, European, Asian, and emerging market sources. No market is out of scope.
📊 Historical Data from Day One
From the moment your pipeline launches, we begin building a proprietary historical database of your collected financial signals — data you own completely and that compounds in value over time as your backtest depth and signal history grows.
Compliance & Ethical Framework for Financial Data Scraping
In the investment industry, compliance is not optional. Here’s the ethical and legal framework that governs responsible financial data extraction:
✅ Compliant Financial Scraping Practices
- Collect only publicly displayed financial information
- Respect website terms of service and robots.txt guidelines
- Implement appropriate request rate limiting on all scrapers
- Use data only for legitimate investment research purposes
- Never use scraped data as the basis for insider trading
- Comply with securities regulations in all applicable jurisdictions
- Maintain data security and access controls for extracted data
- Document data sources and collection methodologies for compliance
- Apply appropriate data retention and disposal policies
- Consult legal counsel for jurisdiction-specific requirements
❌ Non-Compliant Practices to Avoid
- Collecting material non-public information through unauthorized access
- Using scraped data as the sole basis for trades that may constitute market manipulation
- Bypassing authentication or security measures on financial portals
- Sharing or selling proprietary scraped financial data without permission
- Collecting personal financial data of individuals without legal basis
- Violating database copyright through systematic extraction of protected datasets
- Ignoring data vendor terms that restrict downstream use of derived data
- Sending requests that overwhelm financial data systems or cause harm
Critical Compliance Note: While collecting publicly available financial data for investment research is generally legal, the investment industry operates under specific regulatory frameworks (SEC regulations, MiFID II, GDPR for European firms) that govern data collection and use. The distinction between public data and material non-public information (MNPI) is particularly important. Always consult your compliance officer and legal counsel before implementing financial data scraping programs at institutional scale. MyDataScraper provides compliance guidance as part of every financial data project.
Frequently Asked Questions
Is scraping publicly available financial data legal for investment purposes?
Collecting publicly available financial data for legitimate investment research purposes is generally legal, as confirmed by landmark cases including hiQ v. LinkedIn. SEC-filed documents are explicitly public record designed for investor access. However, the investment industry has specific regulatory requirements around data use, MNPI, and market manipulation that must be considered. MyDataScraper builds compliance considerations into every financial data project and recommends consulting compliance counsel for institutional applications.
How does web scraping compare to Bloomberg or FactSet for financial data?
Bloomberg and FactSet provide excellent core market data — but at enormous cost, with standardized coverage, and zero access to alternative data signals. Web scraping complements these vendors by providing alternative data (job postings, news sentiment, web traffic, pricing signals), covering sources vendors don’t include, delivering data faster, and dramatically reducing the cost per data point for coverage expansion. Most sophisticated investors use both: vendor feeds for core data, custom scraping for differentiated signals.
What financial data formats can be delivered?
We deliver financial data in CSV, JSON, or Excel — and can integrate directly with Python/R environments via automated file delivery or API, push to SQL databases (PostgreSQL, MySQL, SQL Server), NoSQL databases (MongoDB), time series databases (InfluxDB, TimescaleDB), cloud data warehouses (BigQuery, Snowflake, Redshift), and portfolio management or risk systems via custom integration.
How quickly is financial data delivered after publication?
Delivery speed depends on the data type and configuration. For high-priority data like SEC 8-K filings, earnings releases, or real-time price data — delivery can be configured within minutes of publication. For less time-sensitive alternative data signals like job posting trends or news sentiment aggregation — daily delivery is standard. We configure the collection frequency and delivery timing to match your investment process requirements.
Can historical financial data be collected for backtesting?
Yes — many financial websites and regulatory databases maintain extensive historical records accessible for systematic extraction. For new signal categories, we build historical databases from the project start date forward. The depth of available historical data varies by source and data type. We assess historical data availability for your specific requirements as part of the project scoping process.
How many securities or financial instruments can be monitored?
Our infrastructure scales to any coverage universe. We’ve built solutions covering individual portfolios of 50 positions through to systematic monitoring of 5,000+ equities across multiple markets simultaneously. Coverage breadth scales without proportional cost increases — making comprehensive universe monitoring accessible to firms of any AUM size. Contact us for a quote specific to your coverage requirements.
How quickly can a financial data scraping project be launched?
Standard financial data extraction projects are built and delivering data within 5 to 10 business days of project kick-off, depending on coverage scope, source complexity, and integration requirements. Simpler projects (single source, standard delivery) can often be launched faster. Contact our team today for a timeline estimate specific to your financial data requirements.
The Information Edge in Financial Markets Belongs to Those Who Build Better Data Pipelines

In financial markets, information asymmetry is the source of all investment returns. The investor who systematically collects more financial data, from more sources, faster than consensus — and builds better analytical processes on top of that data — will outperform over time. This truth has driven Wall Street’s most sophisticated firms to invest hundreds of millions in data infrastructure. And in 2026, it’s driving a generation of independent investors, boutique investment firms, and fintech companies to build their own data advantage through web scraping for financial data.
The good news is that the technology and expertise to build professional-grade financial data extraction pipelines is now accessible to any investment organization — regardless of size or budget. Custom solutions that deliver investment-grade financial intelligence from alternative data sources, regulatory filings, economic databases, and market portals are no longer just for trillion-dollar asset managers. They’re for anyone committed to making better investment decisions with better data.
At MyDataScraper, we build custom financial data extraction solutions tailored to your investment strategy, coverage universe, and analytical workflow. Whether you need real-time earnings release monitoring, alternative data signal construction, comprehensive SEC filing extraction, economic indicator databases, or cryptocurrency market intelligence — we deliver clean, structured, investment-grade data in CSV, JSON, or Excel, integrated into your research systems, on any schedule your investment process demands.
The data edge in financial markets is built — not bought. It’s time to start building yours.
Custom Financial Data Extraction
Built for Your Investment Strategy
Free consultation. Investment-domain expertise. Fast delivery. Tell us your coverage universe, your data requirements, and your research workflow — and we’ll design the automated financial data pipeline that gives you the edge your investment process needs.
📩 Contact MyDataScraper — Free Consultation Visit www.mydatascraper.com to explore all our data extraction services.