Introduction: The Market Research Revolution Nobody Is Talking About
Imagine walking into a business meeting armed with real-time data on exactly what your competitors are doing, what your customers are saying, what prices are dominating the market, and which emerging trends are about to reshape your industry — all gathered automatically, overnight, while you were sleeping. Sounds like something only Fortune 500 companies with massive research budgets can afford, right?
Wrong. In 2026, web scraping for market research has made this level of intelligence accessible to businesses of every size. From solo entrepreneurs and startup founders to enterprise marketing teams and dedicated market research agencies, automated data extraction is fundamentally changing how organizations understand their markets, track competitors, and listen to consumers.
The old way of doing market research — expensive surveys, slow focus groups, manual competitor analysis, and outdated industry reports — is rapidly being replaced by something far more powerful: real-time, large-scale, automated web data collection. And the businesses that adopt this approach early are gaining a compounding intelligence advantage that is very difficult for slower competitors to overcome.
In this comprehensive guide, we’ll explore exactly how market research data extraction works, the most valuable use cases across different industries, what kinds of data can be collected, and how MyDataScraper builds custom web scraping solutions that turn publicly available web data into your most powerful strategic asset.
💡 Key Insight: The global market research industry is valued at over $82 billion in 2026. Yet the fastest-growing segment within it is automated digital data collection — with businesses increasingly turning to web scraping as their primary tool for gathering competitive and consumer intelligence at scale.
What Is Web Scraping for Market Research?
At its core, web scraping for market research is the automated collection of publicly available data from websites, online platforms, forums, review sites, news sources, and social media — specifically for the purpose of understanding markets, competitors, consumers, and industry trends.
It’s the digital equivalent of having an army of analysts constantly monitoring the entire internet and delivering organized, actionable intelligence reports to your desk every single day. Except this army works 24/7, never misses a data point, and costs a fraction of what a human research team would.
Here’s what makes market research data extraction fundamentally different from traditional research methods:
| Dimension | Traditional Market Research | Web Scraping for Market Research |
|---|---|---|
| Speed | Weeks to months for surveys & reports | Real-time or daily data collection |
| Scale | Limited sample sizes | Millions of data points simultaneously |
| Cost | High — surveys, panels, analysts | Low — automated collection at scale |
| Freshness | Often outdated by publication time | Always current — collected continuously |
| Coverage | Narrow focus areas | Entire market ecosystem monitored |
| Objectivity | Subject to survey bias | Based on actual observed behavior & data |
| Customization | Standardized reports | Fully tailored to your exact needs |
Why Web Scraping Is Transforming Market Research in 2026
The internet has become the world’s largest and most continuously updated market research database. Every product review, social media post, news article, job listing, pricing update, and forum discussion is a data point that reveals something meaningful about your market. The challenge has never been finding the data — it’s always been collecting and making sense of it at scale.
Internet users worldwide generating enormous volumes of publicly accessible market data every single day
Bytes of data generated daily online — a virtually unlzited source of market intelligence waiting to be extracted
Of business leaders say real-time market intelligence is now a critical competitive advantage for their organization
Reduction in research costs reported by companies that switched from traditional methods to automated web data collection
The businesses winning in 2026 aren’t necessarily the ones with the biggest budgets — they’re the ones with the best data pipelines. Competitive intelligence scraping gives organizations of all sizes the ability to monitor their competitive landscape in real time, spot emerging opportunities before they become obvious, and make strategic decisions grounded in actual market evidence rather than assumptions.
“Without data, you’re just another person with an opinion. In 2026, the businesses that build systematic data collection into their market research process don’t just make better decisions — they make decisions their competitors literally cannot match.” — Market Strategy Perspective, 2026
10 High-Impact Use Cases of Web Scraping for Market Research
Let’s get specific. Here are the most powerful and widely adopted applications of market research data extraction across different business functions and industries:
Competitive Intelligence
Track competitor websites, pricing pages, product launches, marketing campaigns, job postings, and press releases automatically to build a comprehensive picture of competitive activity.
Consumer Sentiment Analysis
Scrape product reviews, social media comments, Reddit threads, and Q&A forums to understand what consumers truly think about products, brands, and market trends.
Industry Trend Tracking
Monitor news sites, industry publications, analyst blogs, and regulatory databases to identify emerging trends before they reach mainstream awareness.
Pricing Intelligence
Collect pricing data across competitors and marketplaces to understand market price ranges, identify pricing gaps, and optimize your own pricing strategy dynamically.
Brand Monitoring
Track mentions of your brand and competitors across news sites, blogs, forums, and review platforms to manage reputation and respond to market perception in real time.
Target Audience Research
Analyze online communities, forums, and social platforms where your target audience is active to understand their language, pain points, preferences, and buying motivations.
Product & Feature Analysis
Extract product specifications, features, and customer feedback from competitor listings and review platforms to identify market gaps and product development opportunities.
Job Market Intelligence
Scrape job posting sites to understand competitor hiring trends, technology adoption, expansion plans, and talent strategies — a goldmine for competitive intelligence.
Geographic Market Analysis
Collect regional pricing, product availability, and competitor presence data to identify underserved geographic markets and expansion opportunities.
Financial & Economic Research
Extract financial data, market indicators, commodity prices, and economic metrics from public databases and financial platforms to power investment research and business planning.
Where to Find Market Research Data: Key Sources You Can Scrape
One of the greatest advantages of web scraping for market research is the sheer diversity of data sources available. The open web is filled with valuable market intelligence — you just need the right tools to collect it. Here are the primary categories of data sources that businesses extract market research data from:
1. E-Commerce Platforms
Amazon, eBay, Walmart, and niche e-commerce stores are goldmines of market data. Product listings reveal pricing strategies, feature positioning, and competitive assortments. Customer reviews expose genuine consumer sentiment. Bestseller rankings highlight market demand trends. Scraping these platforms gives you a ground-level view of the competitive landscape in any product category.
2. Review & Rating Platforms
Sites like Google Reviews, Trustpilot, Yelp, G2, Capterra, and TripAdvisor host millions of authentic consumer opinions. Consumer insights data scraping from these platforms reveals what customers love, what frustrates them, and what they wish existed — raw market research data that no survey can fully replicate.
3. Social Media & Online Communities
Reddit communities, Quora discussions, Twitter/X conversations, LinkedIn posts, and niche online forums are where real consumer conversations happen. Scraping these platforms for mentions of your industry, product category, or competitors reveals unfiltered consumer attitudes and emerging trends in their earliest stages.
4. News & Industry Publications
Monitoring news sites, trade publications, analyst blogs, and press release databases provides real-time intelligence on industry developments, competitor announcements, regulatory changes, and market-moving events. Industry trends data extraction from these sources keeps your research team perpetually informed.
5. Job Listing Platforms
LinkedIn, Indeed, Glassdoor, and company career pages reveal competitor hiring activity, technology stacks, expansion plans, and organizational priorities. A competitor suddenly posting 20 software engineering roles in a specific city? That’s a signal worth tracking for any market researcher or competitive intelligence analyst.
6. Government & Public Databases
Patent databases, business registries, regulatory filings, import/export records, and court documents are all publicly available sources of valuable market intelligence. Scraping these databases can reveal competitor innovations, market entry activities, and regulatory developments.
7. Competitor Websites
Monitoring competitor websites directly — their product pages, pricing pages, blog content, case studies, and announcements — provides a continuous stream of competitive intelligence. Tracking changes over time reveals strategic pivots, new product directions, and pricing adjustments.
🌐 Pro Tip: The most powerful market research data pipelines don’t rely on a single source — they aggregate data from multiple sources simultaneously, creating a rich, multi-dimensional view of the market. MyDataScraper specializes in building exactly these kinds of multi-source market research data extraction solutions.
Industries That Benefit Most from Market Research Web Scraping
While virtually every industry can benefit from automated market research data collection, here are the sectors where competitive intelligence scraping delivers the most immediate and measurable impact:
| Industry | Key Data Extracted | Primary Benefit |
|---|---|---|
| Retail & E-Commerce | Competitor pricing, product assortments, promotions, customer reviews | Dynamic pricing, assortment optimization, market positioning |
| Financial Services | Market indicators, competitor rates, economic data, regulatory filings | Investment research, risk assessment, product benchmarking |
| Technology & SaaS | Feature comparisons, pricing tiers, user reviews, job postings | Product roadmap decisions, competitive positioning, market sizing |
| Healthcare & Pharma | Clinical trial data, drug pricing, regulatory approvals, research publications | Drug development intelligence, market access strategy |
| Travel & Hospitality | Hotel rates, flight prices, review sentiment, occupancy data | Revenue management, competitive pricing, service improvement |
| Consumer Goods (FMCG) | Shelf pricing, promotions, consumer reviews, distribution data | Brand health monitoring, promotional strategy, distribution insights |
| Market Research Agencies | Cross-industry data for client reports and intelligence deliverables | Richer reports, faster turnaround, lower research costs |
| Real Estate | Property listings, pricing trends, rental data, market transactions | Investment analysis, market timing, portfolio management |
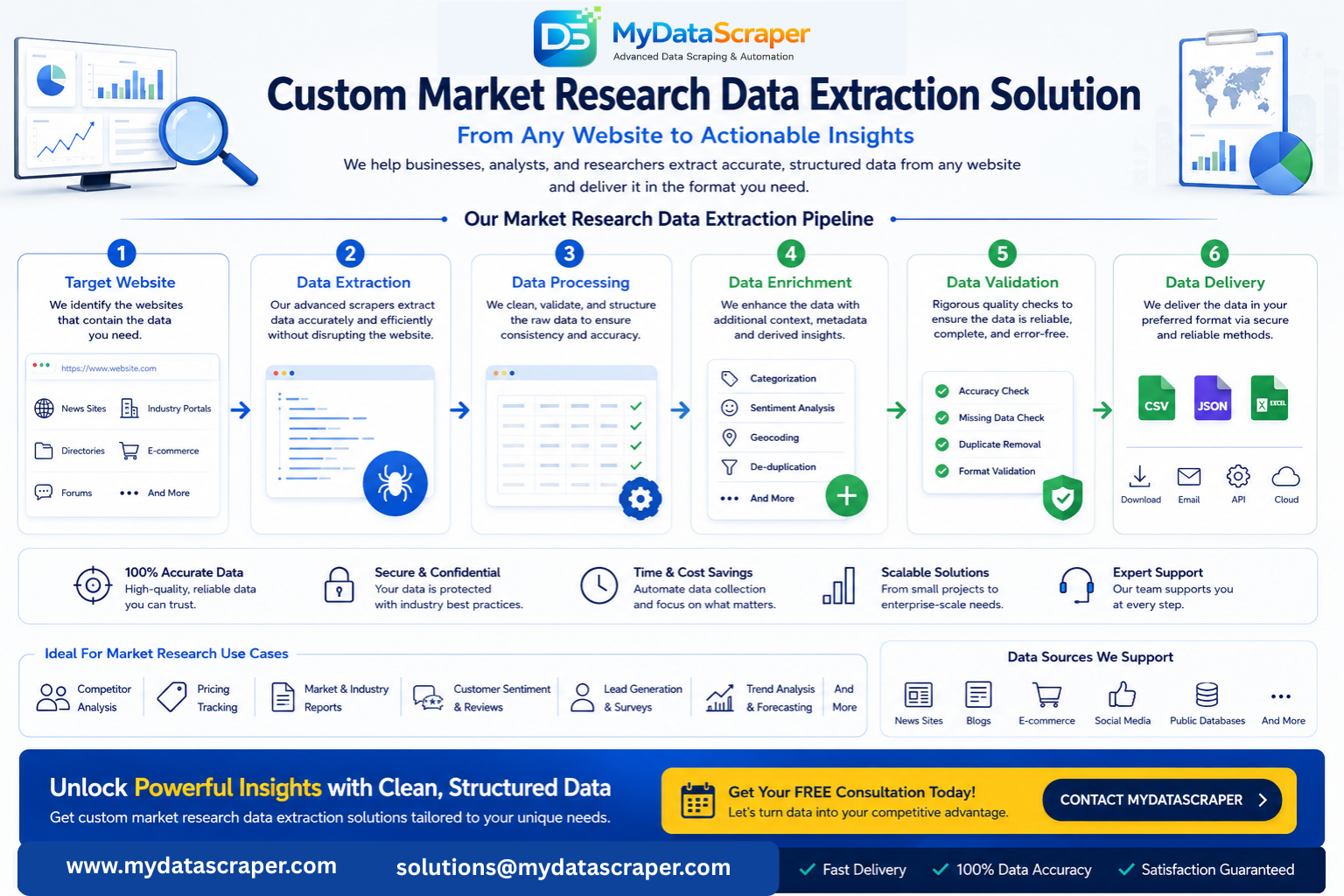
How MyDataScraper Powers Your Market Research with Custom Data Extraction
Generic scraping tools are built for generic problems. But market research data needs are highly specific — the sources, data fields, update frequency, and delivery formats vary enormously from one business to another. That’s exactly why MyDataScraper builds custom, scalable web scraping solutions tailored precisely to your research objectives.
Here’s how our process works from start to finish:
-
Discovery & Research Design
We start by deeply understanding your market research goals, target data sources, competitive landscape, and how you plan to use the extracted data. This consultation shapes the entire project design and ensures we collect exactly the data that matters most to your business.
-
Custom Scraper Architecture
Our experienced development team designs and builds scrapers specifically engineered for your target websites. We handle complex challenges including JavaScript-rendered content, pagination, login-free data access, anti-bot countermeasures, IP rotation, and CAPTCHA management.
-
Multi-Source Data Aggregation
For comprehensive market research, we often build solutions that collect data from multiple sources simultaneously — competitor websites, review platforms, news sources, social platforms, and public databases — and consolidate everything into a unified, coherent dataset.
-
Data Cleaning & Enrichment
Raw scraped data is processed through our cleaning and validation pipeline — removing duplicates, standardizing formats, filling gaps, and enriching records with additional context. You receive clean, analysis-ready data, not raw HTML noise.
-
Flexible Delivery in Your Preferred Format
Your market research data is delivered in CSV, JSON, or Excel — whichever format fits your workflow best. We can automate delivery via email, cloud storage, API, or direct database integration on any schedule you need.
-
Ongoing Monitoring & Maintenance
Markets evolve and websites change. Our team continuously monitors your scrapers and adapts them to any structural changes in target sites, ensuring uninterrupted data delivery. You get consistent, reliable intelligence without managing any technical complexity.
📊 Ready to Supercharge Your Market Research?
Stop guessing. Start knowing. MyDataScraper builds custom market research data extraction solutions that deliver real-time competitive intelligence, consumer insights, and industry trend data — in CSV, JSON, or Excel. Let’s build your data advantage together.
Get Your Free Consultation →Case Study: How a Market Research Agency Tripled Its Client Output Using Web Scraping
Consider a mid-size market research agency serving clients in the consumer goods, retail, and technology sectors. Before adopting web scraping, their research process was deeply manual — analysts spent the majority of their time collecting data rather than analyzing it. Client deliverables took 4-6 weeks, data was often outdated by delivery, and scaling the business meant hiring more analysts.
The Challenges They Faced
- Analysts spending 70%+ of their time on data collection rather than analysis and insights
- Reports relying on data that was weeks or months old by the time clients received it
- Inability to monitor competitor activities and market trends continuously for clients
- High operational costs due to manual research labor at scale
- Losing competitive pitches to agencies promising faster, more data-rich deliverables
The MyDataScraper Solution
After partnering with MyDataScraper, we built a comprehensive market research data extraction infrastructure covering:
- Automated daily scraping of 150+ industry news sources and trade publications across 6 sectors
- Competitor monitoring across 40+ websites for each of their top 12 clients — tracking pricing, content, product changes, and announcements
- Consumer sentiment extraction from 20+ review platforms and online communities
- Social listening data pipeline aggregating relevant conversations from Reddit, forums, and public social media
- All data delivered in structured Excel reports, automatically organized by client and data category
The Results (Within 6 Months)
Increase in client report output — delivering more research to more clients without adding headcount
Reduction in time analysts spent on data collection — freeing them to focus on analysis and insights
Turnaround time reduced from 4-6 weeks to under 2 weeks for comprehensive market intelligence reports
Revenue growth as the agency won new clients specifically on the strength of their data capabilities
✅ Bottom Line: By automating data collection with custom web scraping, this agency transformed from a labor-intensive research business into a high-efficiency intelligence operation — delivering better work, faster, at lower cost, and with greater scalability. This is what market research data extraction can do for your business.
Whether you’re a market research agency looking to scale, a brand manager seeking real-time competitive intelligence, or a business analyst building industry tracking systems — contact MyDataScraper today and let’s design a solution that transforms how you research your market.
Best Practices for Responsible Market Research Data Scraping
Powerful tools come with responsibility. Here are the fundamental principles that guide ethical and effective web scraping for market research:
Focus on Publicly Accessible Data
Collect only data that is publicly visible without authentication. Public pricing pages, published product listings, public reviews, news articles, and open forums are all appropriate sources. Respect login-protected areas and private user data absolutely.
Review and Respect Terms of Service
Each website has its own terms of service governing automated access. Reviewing and adhering to these terms is a core principle of responsible scraping. Working with professional services ensures these boundaries are navigated appropriately.
Implement Intelligent Rate Limiting
Well-designed scrapers operate at speeds that don’t disrupt the target server’s normal operation. Implementing proper delays, request pacing, and off-peak scheduling is both an ethical practice and a technical best practice.
Comply with Data Privacy Regulations
GDPR, CCPA, and other regional data privacy laws govern how personal data can be collected and used. Ensure your market research scraping activities — particularly when collecting any data that could identify individuals — comply fully with applicable regulations.
Use Data Responsibly
Extracted market research data should be used for legitimate business intelligence purposes. Use data to make better decisions, serve customers better, and build stronger products — not to engage in anti-competitive practices.
Partner with Experienced Professionals
The safest, most effective way to run market research web scraping programs is to work with a specialist provider who understands both the technical complexities and the ethical/legal landscape. MyDataScraper builds compliant, reliable, and highly effective data extraction solutions for market research applications.
⚠️ Important: While web scraping publicly available data is generally permissible, always consult with a legal professional regarding your specific use case, particularly when operating across multiple jurisdictions with different data protection laws.
Frequently Asked Questions
What types of market research data can web scraping collect?
Web scraping can collect virtually any publicly available market data — competitor pricing, product features, customer reviews, brand mentions, news coverage, job postings, social media conversations, financial data, and much more. The specific data extracted depends entirely on your research objectives and target sources. Contact us to discuss your specific data needs.
How is web scraping better than buying industry reports?
Traditional industry reports are expensive, infrequent, and cover broad markets rather than your specific competitive landscape. Web scraping for market research gives you continuous, real-time intelligence specifically tailored to your exact competitors, target markets, and research questions — at a fraction of the cost of syndicated reports.
How often will I receive updated market research data?
Data delivery frequency is entirely configurable based on your needs. Many clients receive daily intelligence reports. Others require real-time monitoring for fast-moving markets like financial services or e-commerce. Some research projects require one-time bulk data extractions. We design the scraping schedule around your specific requirements.
Can you scrape data from social media for consumer research?
Yes — public social media content, forums, Reddit communities, review platforms, and online discussion boards are valuable sources of authentic consumer insights. We build scrapers that ethically collect publicly available conversations and sentiment data relevant to your research objectives, without accessing private accounts or violating platform terms.
What format will I receive my market research data in?
We deliver data in CSV, JSON, or Excel — whichever format best suits your workflow and analysis tools. We can also automate delivery via email, cloud storage, or direct API integration to your analytics platforms or BI tools like Tableau, Power BI, or Google Data Studio.
How quickly can a market research scraping project be set up?
Most projects are set up within 3 to 7 business days, depending on the complexity of target websites and the scope of data requirements. Simple single-source projects can often be delivered even faster. Reach out to us at mydatascraper.com/contact-us for a timeline estimate specific to your project.
Do I need a technical team to work with MyDataScraper?
Absolutely not. We handle 100% of the technical work — from scraper development and infrastructure management to data cleaning and automated delivery. Your team simply receives clean, structured market research data ready for analysis. No coding, no infrastructure management, no technical expertise required on your end.
Conclusion: Stop Researching in the Dark — Start Extracting Real Market Intelligence
Market research has always been the foundation of smart business strategy. But in 2026, the speed, scale, and sophistication demanded by competitive markets has completely outgrown what traditional research methods can deliver. The businesses that are winning today aren’t the ones with the biggest research budgets — they’re the ones with the most efficient, continuous, and comprehensive data pipelines.
Web scraping for market research is the engine behind this new kind of intelligence. It gives you real-time visibility into competitor activities, authentic consumer sentiment at scale, emerging industry trends before they go mainstream, and the kind of data-driven confidence that transforms guesswork into strategy.
Whether you’re a market research agency looking to deliver richer client work at higher speed, a brand manager seeking continuous competitive intelligence, a product team wanting to understand customer needs at scale, or a business analyst building industry monitoring systems — MyDataScraper has the expertise, infrastructure, and dedication to build exactly the solution you need.
We provide custom, scalable web scraping solutions for market research, e-commerce, and real estate — with data delivered in CSV, JSON, or Excel on any schedule you require. Our team manages every technical detail so you can focus entirely on what matters: turning great data into great decisions.
🎯 Transform Your Market Research Today
Get a free, no-obligation consultation with our team. Tell us what market intelligence you need — competitors, consumers, trends, pricing, reviews — and we’ll design a custom data extraction solution that delivers it continuously, accurately, and affordably.
Contact MyDataScraper for Free →Visit www.mydatascraper.com to explore all our data extraction services.